Anticipation
I realize you probably came here because the title had a catchy ant pun, and because you were hoping to read about some absurd technical feat related to colony management. We'll get to that. But I want to open with a story.
There's a song by the band Gunship, called Fly For Your Life, which is set to pieces of a short film called Paths of Hate. Which is a gorgeous animation about how two enemy pilots are twisted by war into demons that absolutely hate each other, and is a poignant distillation of how humans can abandon their humanity and become monsters. I keep coming back to this video. I must have watched it dozens of times now. I get the anti-war message, but the reason I come back to it is not because it captures something about war. It's because there's a moment in the film where both pilots are flying away from each other, out of ammo, out of gas, their planes a wreck, their bodies partially broken, and impulsively, at the same time, they both turn back, so possessed by hate that they must finish what they started... and that's what it's like to be in my brain, facing an impossible challenge. It's not hate, but it is that single minded obsession, that part of me that is so inflamed by the task ahead of me, that it's not about victory or defeat, but an almost all consuming self-annihilation in the crucible of the challenge.
When one of my friends linked to the SWARM challenge which had just been the top of Hacker News that day, I knew. Seeing the leaderboard solidified it. The first place prize being a trip to Hawaii just made it more inevitable. I opened up VSCode knowing that I was going to fall into this trap. That the challenge was simple and powerful enough that it would be an obsession.
As the naming suggests, the challenge is managing an ant colony. 200 ants on a 128x128 grid have 2000 ticks to find and collect food across 12 different map types. You write a single shared brain program (in a custom assembly language called ant-ssembly) that controls all of them, scoring 0-1000 based on average food collected. Ants can drop pheromones, smell pheromones, detect other ants, and wander around. The maps range from pleas-ant open fields, to a hellscape of jagged walls, to mazes.
Nowadays, I don't actually write code by hand if I can avoid it. I even wrote a harness so I could manage a swarm of agents without too much friction (there's still a lot of friction). So I spun up Claude Code and Claude Code and Claude Code and Gemini CLI for good measure, and set out to work. The biggest issue in these kinds of problems, I've learned, is keeping the workstreams separate, and maintaining context. This felt like the kind of scenario where running parallel experiments would be extremely fruitful.
So I copied the full context of the challenge, and told claude_1 (Death Knight) to go research previous challenges like this, I remembered google had had something similar a few years ago, and surely ants were a solved problem. claude_2 (Gnomish Airship) was sent to research real ant behavior and how we might apply it. Claude_3 (Mage) was given the task of scraping the challenge site, and building a harness that would allow us to run the challenge tests locally. Gemini started a parallel research thread on ant-colony sims, from the math side.
A critical element of any AI workflow is to have a testing harness. I recommend a CLI, agents seem to understand those well, but a workflow that can't be validated will lead to agents confidently declaring something didn't work for a completely hallucinated reason. If you're using a language that supports it (so not ant-ssembly) unit tests are your best friend. The core idea is you must give agents the tools to actually understand why their code failed, rather than a juicy sounding explanation. Otherwise you might burn a week's worth of tokens in a few hours and wind up with totally incorrect theories about gradient saturation in ant-colonies. (I'm not bitter about this at all). This is also, crucially, where I decided I would not write a higher level language on top of ant-ssembly, I was coming fresh off my Advent of Code assembly challenge and felt pretty confident that I wouldn't need anything like that. After all, eight registers and a few hundred instructions was more than enough. With the help of my team, surely we'd never get confused about what a given register held at a given time.
The research churned along and I set some ground rules. Yes, this was a GitHub repository, but worktrees are a pain to set up and manage, so we'd just do an ancient version of source control. No deletion of files, every new version of code goes into a new file. Files are named agent_number_what_the_file_does_version_number. A very easy naming convention to remember.
Further, we'd have an EXPERIMENTS.MD file, a log of the canonical state of the project, what we tried, why it worked, why it failed, what not to try, etc. Having a centralized source of truth would keep us from going in circles and would let us test that behaviors worked as expected. With the harness to validate against, we could be confident that things going into experiments.md would be thoroughly tested. As the research findings came in, I felt confident we could get into the top 10. If not first place. I could almost taste the fruity drink with an umbrella on a Hawaii beach.
So I began to code in earnest. The first problem was merely coming up with a search pattern for ants. There's a few different ant-ecendents, but many of them rely on ants having a sensor range bigger than 1, or being able to detect walls and pheromones at range. We had to operate within the constraint of a single tile's worth of sight. Early approaches were the simplest they could be. Randomized walks in various directions, when you find food you immediately head back. If you hit a wall, re-randomize your direction, and try again.
It was not the most promising opening I've ever seen, but it got the ants wiggling, and it was satisfying to see them move visually. Much like making a good harness is critical for agents to succeed, if you're running a challenge, it's really important to have feedback loops that feel real and tangible. Hats off to Moment here, the entire challenge website felt tangible. I could see the ants move, the feedback was direct, I could trace pheromone maps, and individual ants. I recognize a work of love when I see it, and the entire challenge reads like people who care, building a thing they want other people to play with. Just look at it:
I read through the research, several promising avenues about distributed coordination emerged. I don't suggest you read all of these, unless you really like ants, but I did spend most of the first couple hours of the project reading through these and imagining how we could apply them within our constraints. (Also ants are cool. Check out the paper on desert ants, and the liquid brain one if you just want "papers that Felipe found neat" even if they weren't super applicable. The Google challenge ones are genuinely very cool too.)
Ant Biology & Foraging
- No entry signal in ant foraging - Nature
- The role of multiple pheromones in food recruitment - J. Exp. Biology
- Desert ants compensate for navigation uncertainty - J. Exp. Biology
- Ants combine systematic meandering and correlated random walks - PMC
- Negative feedback: ants choose unoccupied food sources - Royal Society
- Decay rates of attractive and repellent pheromones - Insectes Sociaux
- Modulation of pheromone trail strength with food quality in Pharaoh's ant - ScienceDirect
- Ant agent-based model: roles of attractive and repellent pheromones - ScienceDirect
- Trail geometry gives polarity to ant foraging networks - Nature
- Foraging ants as liquid brains - PNAS 2025
- Diverse stochasticity leads a colony to optimal foraging - ScienceDirect
Lévy Flights & Search Theory
- Lévy flight foraging hypothesis - Wikipedia
- Intermittent inverse-square Lévy walks are optimal - Science Advances
- Optimal Lévy-flight foraging in a finite landscape - Royal Society
- On the Search Efficiency of Parallel Lévy Walks on Z2 - HAL 2020
Theoretical CS / Multi-Agent Search
Prior Competitions
- xathis winning bot - GitHub
- Google AI Challenge Post Mortem - decompilinglife
- Ants Post Mortem - codetiger
- Ant Colony Post Mortem - runevision
- AI Challenge Ants Post Mortem - LessWrong
I can't say I read them all in detail, but what I needed was the texture of the field. Agents tend to bias towards shallow, generally applicable solutions. They're eager coders without domain expertise, they don't know what they don't know and are happy to lie to you about what they do understand. So if you want to get good results, you need to do the research and hold the context in your brain. Because my brain is only so-so, it helps me to have it in some files I can browse later. Here my strategy was to name them all things like RESEARCH_ANTS.MD and RESEARCH_PATHFINDING.MD. This was a mistake, and in hindsight the files were missing three bits of information:
- Chronological information on when the research happened relative to the project
- An easy way to gather related information
- An actual clear indicator of where it was applicable.
A folder with timestamped files, and an INDEX.MD with the metadata would have been a much stronger approach. Having an agent to maintain the INDEX.MD is probably the way to go.I learned that having a standing instruction like "when you're done researching, read INDEX.MD and update it", you'll find you often have to manually remind the agent of this because they'll "do it later" and when you remind them they'll promise to "be more on top of it". A hook of some kind works better. Either an "on session end" hook or a cron job, depending on the length of your project.
Regardless, I was now armed with the knowledge of an amateur but highly specialized entomologist. I'd gotten to do the most enjoyable part of the project, which is doing the reading and writing the basic working code that lets you know that yes, you are some kind of programming god. Which is a great time to wrap up a project. Before the regret of your bad decisions can begin to catch up with you.
Instead I decided that random walks were not really where we wanted to be.
I'd just finished reading the paper on Lévy flights. I didn't have a clear idea of how to implement a Lévy flight, or what a Lévy flight even was, but the gist of it seemed to be that you could make a power law distribution to cover space efficiently, and that this would let me spread my ants out into patterns of exploration that were more efficient than "walk randomly, hope for the best".
"A power law distribution" sounds very fancy, but the core algorithm is actually relatively simple. An ant picks a heading and a length, e.g. north 18 moves. You use a distribution to make it so you do a lot of short local walks and then take a long walk away. Which is how animals in nature do most of their exploring, you search a local area, get bored, go far away, search that new area, repeat.
This was an immediate success. On open maps like Prairie and Open, we went from 68 points to 190. It felt like a massive win, for a relatively small amount of work. The distribution at the time was totally arbitrary numbers I'd had Claude pull from thin air as I let it deal with the implementation details of what register should hold the data.
The current top score on the leaderboard was 700 points, but I felt like I was already well on my way to dethroning simonwongwong. Only 510 points away.
While I was working on Lévy walks, the other agents did not sit idle. I had one exploring the ongoing and nagging problem of walls, which inconsiderately seemed to block our best efforts, and another seeing if we could have ants leave pheromone trails when returning from food.
The pheromone approach just didn't seem to work. Claude told me that the short detection range meant that approach was fundamentally not going to work. Ants just never saw the trails. This was consistent across four trials of varying intensity. We added it to the experiments log and decided we'd do more research on how to use pheromones within our context. Maybe something about the density of ants in a given zone to bias exploration?
I turned my attention back to the walls. Maps like Fortress and Gauntlet scored zero points, and the reason was plain to see
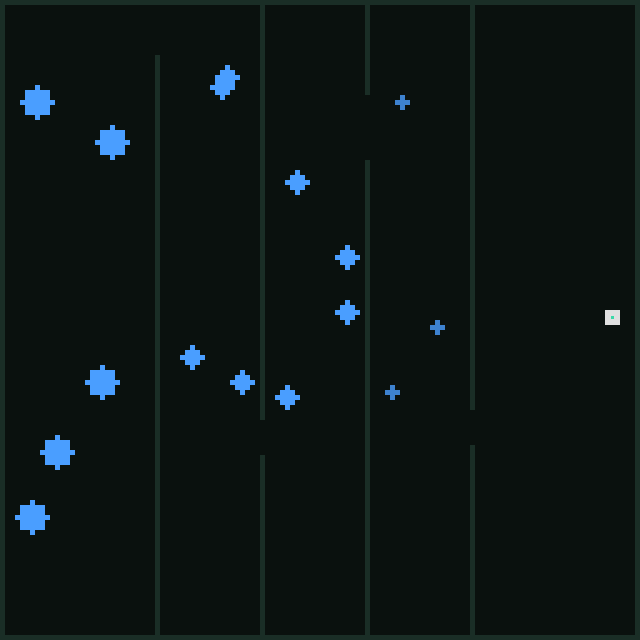
Walls, walls everywhere.
So of course I decided the best course of action was to throw everything I'd read in every paper into my code all at once. Dual gradient trails, anti-trail exploration, SNIFF-all-4 navigation, a new weight for Lévy Flights, all of it. The score immediately dropped to 23 points.
Perhaps it had been a tad ambitious. We wanted the score to go up. Claude agreed.
The anti-pheromone was apparently causing the ants to collapse into the same regions by collectively avoiding too much of the map, which ruined exploration. We dutifully recorded the observation and narrowed in deeper, the best way to deal with walls would be to be aware of walls, not some trick with pheromones.
Fortunately, code works best when you break it up into parts. So one agent worked on adding trails using the red pheromone channel whenever an ant walked towards the nest, a directional breadcrumb instead of an explicit path to food. Another added fan out logic, splitting the ants into four cohorts each headed in a different cardinal direction at first. This all got rolled into the Lévy Flight changes, and none of it addressed walls. Still, +10 points is +10 points.
The wall logic at the time was basically this:
- PROBE the intended direction
- If wall: try turning clockwise
- If wall: try the counterclockwise direction instead
- If wall: try opposite
This meant that the ants would essentially bounce along the wall. They'd be heading north, hit a wall, go east for a tick, try to go north again, repeat.
The only solution I could see to the wall problem was wall following. What followed was a litany of disasters.
- V3.1: Dedicated 10% of ants as permanent right-hand wall followers. This failed utterly. Walking forward until you find a wall and just following it was not a winning strategy. We recorded that losing 10% of ants to just follow walls meant we did less exploration, which caused our regrettable score drop. Discarded.
- V8-WF: Step refund on wall hit during Lévy flights. The core idea being that if you were headed east, and bumping into a wall, it wouldn't count against your assigned number of moves in that direction. Predictably this led to a lot of stuck ants, and a huge score drop. Again. Some interesting tweaks with pheromone density in the area and probabilistic refunds concluded that yeah, this idea was terrible. What was I even thinking?
- V10i: If you're searching and hit a wall, follow it for 120 moves. -50 points. Discarded.
- V10h: Same as V10i, but three moves. Score unchanged. Discarded.
- V10j: V10h, but 30 steps, and only if you're more than 20 squares away from the home base. -100 points on average in brush, bridge and field. Discarded.
- V14: CW-first wall-following as the entire movement strategy. Score 0. Breaks open space maps. Discarded.
- V21-GT (gap trail): 25-step wall-follow from decision points (not wall hits), plus going home to mark a "gap trail" through openings. -53 points. Discarded. Similar to the homing trails from food, gaps were never spotted with just a one-tile range.
Regretfully, I told Claude to record in both its memory and the experiment log that wall following was a dead end, and to please stop suggesting it.
As a brief digression. Remember that I'd also spun up Gemini on this? By this point it had spent two hours running unsupervised, exhausted its token budget, and produced absolutely nothing useful. I was not especially impressed with my newest collaborator.
So, moderately annoyed at Google and massively annoyed at the walls, I said fuck it. Fine. The walls wouldn't cooperate? It was a beautiful Friday, I was millions of tokens in and had spent the eight hours since I read about the challenge in the clutches of full fledged mania. We were going to do it the hard way.
Searching with Lévy flights still worked well; what we needed was to carry the food home. We'd just… use the same technique we used to find the food to navigate back. That had demonstrably gotten around walls. I honed in on one agent (Troll Axe Thrower) and launched the others in --dangerously-skip-permissions so they could chug along. Then I built the least elegant solution possible.
Broadly, once an ant had food:
- Compute the direction home from its dx/dy displacement, choosing randomly whether to prioritize the X or Y axis first to avoid corner traps tanking the score again.
- If that direction is blocked by a wall, fall back to the existing wall-bounce logic.
- Move and update dx/dy.
- Mark red pheromones on every step as a directional trail.
- 25% of the time, ignore displacement and look for blue pheromones instead, just to unstick from walls.
- At nest: DROP.
After delivery:
- Compute the direction back to the remembered food position using the saved dx/dy from pickup.
- Set up a Lévy walk in that direction for roughly the right number of steps.
- Walk back to the food area and grab more.
Simple. It only took 30ish versions. And it worked. The score rose to 270.
The Ants Go Marching
It had taken some work to deal with juggling the data in assembly, and with Claude trying to access unsupported instructions, but overall, it had been as painless as writing raw assembly could be. I almost wished I'd spent the time writing a higher level language, but now that the gap to first place was narrowing, and we were almost halfway there, it felt foolish to waste a ton of time on an unnecessary abstraction.
I didn't pause to celebrate. The bottom of the top ten was still just shy of 600 points, at least 300 points away. Instead, with the energy of a man trapped in a sinking submarine, I flipped back to my other agents, hoping they'd made progress. The results were mixed.
The three agents (Human Transport, Peon, Zeppelin) had each been tasked with exploring a specific type of map. Human Transport had helpfully decided to name its files with the 1_ prefix, which collided with the prefix Peon was using, so there were a ton of files called 1_ant_exploration_v15j right next to 1_ant_maze_exploration_v14d that were wildly divergent streams. It was fine. I didn't need to reorganize. I could just look at what the workstream was.
Human Transport had been tasked with fixing Gauntlet. Since its first three radical ideas (food trails, which we'd already tried, wall following, also tried, and pheromone gradients, literally already in the code) had not produced results, and had instead cratered the score, it had spent the last 30 minutes slowly tweaking the various parameters that controlled Lévy flights, and celebrating every time the score increased by 1. It proudly announced a +3 increase in overall score. Gauntlet remained firmly at 19 points scored. The +3 score was statistical noise that didn't bear out in practice. It had only cost me 27% of my five hour usage quota to discover this.

I checked back to see if my Gemini quota had restored itself. Turns out that's a 24 hour block, I'd need to wait four more hours until midnight. I would have to soldier on without Gemini 3.1 (Experimental). Perhaps it could join Human Transport's victory parade.
I checked in on Zeppelin, which had been working on chambers. It proudly announced that by tuning the parameters of Lévy flight, it had succeeded in raising our score by an entire 5 points.
I wondered why, exactly, I paid Anthropic $200 a month.
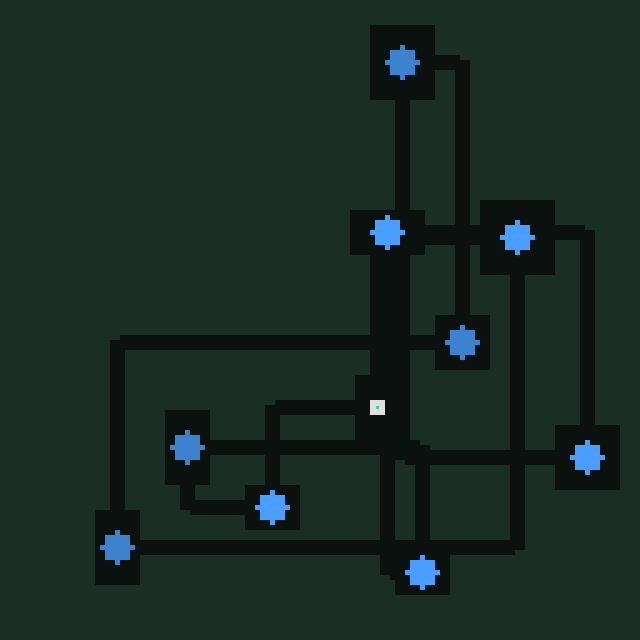
I almost didn't want to open the tab to check on Peon. The dozens of files with names like 2_maze_wall_walking_v17b made me dread that I'd find a well written conclusion that wall walking is, in fact, a dead end, as we'd already proven. Which is why I had to re-read the score three times. 360 points. It had to be an error. We knew that wall following didn't work.
I didn't even read the description. I jumped directly into the code. It looked extremely similar to what we'd tried in the v10 branches. All of which had failed. But I watched the score on the website and the result was undeniable. Following my instructions, Claude had stripped the code to the bare minimum and then explored what worked specifically on mazes. I ran the test suite one more time. 360. I retasked the other workers and made this the base we'd all work from.
The actual score improving idea was simple. It's a well known robotics algorithm called Bug 2 that I had just learned about. Treat wall following as a brief interruption. Its own subroutine. The ant is still a Lévy walker, it just does a 15-step wall trace when it hits something, then goes back to being a Lévy walker.
It was hard to tell exactly why that was more effective than having wall following in the Lévy walk, but it was hard to argue with empirical evidence. Claude reassured me that the difference in score could be attributed the fact that it was a separate process. I hoped that the other workers would have similar breakthroughs. I left Peon working on its own.
Fifteen minutes later it was fiddling with parameters again. I asked it to please focus instead on switching ant "handedness" for half the colony, so wall exploration wouldn't always be left-biased. A quick change, and we picked up another 21 points.
It was around this point,when I was ten hours into the land of ants that Dave noticed someone had posted about the challenge.

I realized that I had not once submitted a score yet. I had figured I would wait until I was sure I was in the top 10. But Dave's question inspired curiosity. I submitted it. #16. Out of 2305. Suddenly 600 felt much more possible than it had before.
It is also where I began to worry. You see, Dave and I are great friends. We've been friends for years. We are also fiercely competitive. When Dave started playing Go, I spent three months playing every day, dreaming of stones and tenukis, until I could reliably beat him. He still trumps me at chess effortlessly. We've politely declined to play each other in Age of Empires 2 (Dave would crush me, and then I'd have to get good, and I can't spare the four months of grinding that would take.) I didn't know who 0xkcd was, or how he'd scored 700+ points. Which made him eminently beatable.
I did know who Dave was. If he threw himself at this challenge with the same single-mindedness I had, I knew two things would happen. One, I'd have to redouble my efforts. Two, Dave would likely come up with something brilliant I hadn't considered and wreck me.
The problem was, I had zero desire to dissuade Dave. If I truly wanted to win, the thing to do would have been to ask him not to participate. Instead, as we discussed multiplayer Slay the Spire II (it's less buggy now), I also shared how I'd ripped the javascript from SWARM, and we discussed his desire to solve the problem with genetic programming, and my innovative method of storing files. I think Dave has wanted to solve a problem with genetic programming almost as long as I've wanted Bayesian Optimization to be a silver bullet that saves the day.

Yes, I took a break to play Slay the Spire II. I had hit my five hour limit with Claude Code, and Lévy no longer looked like a word. My brain needed time to marinate.
Discussing it with Dave helped, though. It sharpened some ideas. It gave them teeth. Saturday morning, bright and early, I spun up five agents, to explore five new ideas, and clear that 600 point barrier. I also brought in my new pinch hitter.
You see, everyone had assured me Codex was the be all, end all, of modern agentic coding, and that soon my job would be made obsolete by its incredible prowess. I felt like twenty dollars to secure a trip to Hawaii and a victory over Dave was a small price to pay. So I acquired a OpenAI pro subscription. With one hand I fed the baby, since it was my turn, and with the other I asked Codex to get caught up with the codebase.
Gemini had once again burned through its token budget in record time. It turns out it was no more able to make "mark gaps in the walls" work this time than the previous time.
I was not deterred, Codex promptly read up on the project and when I asked offered me a plethora of brilliant ideas. Laying a trail back to the food using pheromones. Improved wall following. Marking the gaps in the walls. Maybe having all the ants lay down trails of pheromones as a density map.
Surely, my victory was assured.
You can take an ant to water, but you can't make it think
If Friday was categorized by triumphs, Saturday was the day of the slow, endless grind. Between rounds of slay the spire, diaper changes, one quick grocery trip, and other miscellaneous things, the agents churned along, burning tokens with the intensity of a train conductor shoveling coal into a sputtering locomotive.We'd pulled all the guardrails from wall following, one by one, and it netted another thirty points. We sat at 420. The bottom of the leaderboard was at 500. One breakthrough away.
No breakthrough seemed forthcoming. I was convinced that pheromones were the key. We just needed another working approach. We tried tuning the red pheromones used to indicate direction. No dice. One Claude session (Footman) spent several hours painstakingly tuning parameters until I intervened and asked it to just write a script. The conversations with LLMs went somewhat like this:
"Here's my experiments.md, you can see I tried 12 different variations of pheromone strategies. Density doesn't work. Wall beacons don't work. Pathing to food doesn't work. Directional pheromones only kind of work, and i'm not even sure they're doing anything. Beacons at gates is something we've tried literally 30 different times. Can you suggest ideas?"
"Have you considered using a directional trail to the food?!"
"Yes. It doesn't work."
"What if you split it up into directional beacons?"
"Experiments.md line 1239"
"Wow, it sounds like you need a paradigm shift. Perhaps something like a density gradient?"
"Yeah, that doesn't work either"
"Well, maybe 420 points is the maximum theoretical possible! Good job! We should call it here."
Add your own variation: Gemini with delusions of grandeur, Claude with patient but unhelpful encouragement, ChatGPT with a polished listicle of ten ideas I had absolutely seen before, and Grok failing, with admirable consistency, to grok the problem. I even tried deepseek and whatever mistral.ai is calling their chat model nowadays.
By 8 p.m. I got the dreaded notification every developer hates to see:
"You are approaching your weekly limit. You have used 90% of your token capacity. This limit will reset on Thursday at 11:09 EST."
Given that I was only two days into the challenge, this did not bode well for either my agentic setup or my budget.
We had burned tens of millions of tokens for several +3-point improvements, all accompanied by enthusiastic clapping and victory laps. We had made major architectural changes, orchestrated a full rewrite of the codebase, and somehow lost 50 points in the process. Thanks, Codex.
All we had to show for it was an experiments.md that increasingly suggested nobody should be able to reach the 770 points that simonwongwong's smug score was still holding over my head.
At least I'd helped Dave debug his ant-ssembly, and he now had ants crawling around the maps with some degree of success. He seemed determined to build a blazingly fast Rust emulator and get his iteration loop as tight as possible, which I realized, now way too late, might have saved me a few hundred thousand tokens of output. He also had some unorthodox ideas about how he could stretch the bounds of the challenge. I was half-eager-half dreading seeing what he could produce.
One thing was clear. I needed to preserve tokens at all costs. Claude Opus 4.6 with extended thinking is, in my opinion, the best code reasoning model on the market. So that remaining 10% of the weekly budget had to be hoarded. Gemini was already exhausted, and frankly, might as well not exist for all the good it was doing us. I would have to lean on Codex, and worse, write code by hand.
My conversation with Codex was as circular as the preceding ones. It tried to convince me a hundred points lay in incremental improvements. I still had a nagging doubt: why did laying pheromone trails to the food not work? I accepted they were too narrow, but surely at least on open maps, it should give us some score improvement.
It was the idea that had stuck with me. It felt like I had tried everything. I had insisted that we were at a local maximum, that I could accept some score loss to improve Fortress. One Claude session had gotten Fortress from 52 points to 220 (at the cost of a total score of 300). It didn't generalize. I had told the agents to really dig into what ant behaviors were causing the regressions, and I had an inventory of confident analysis on the various ways we had failed.
Dutifully, Codex produced another version of pheromone dropping. Dropping yellow pheromone trails back to food. Without having to manage five other agents, while I waited for a smug "as our data shows, that approach is doomed" message to finish generating, I looked at the ants in the simulator, crawling around, wandering around walls, getting stuck in infinite loops, not dropping any pheromones…
The code was broken. I clicked back to Codex, and read a totally plausible explanation about why the trails didn't work and our score had dropped 200 points. You see the trails that had never been dropped on the map had caused all the ants to cluster, and that was the reason our score had dropped. Not the fact that the code changes had clobbered a register and caused wall following to stop working entirely. We should immediately abandon this doomed idea, maybe we could tune Lévy Walks further? That had produced a fantastic two point improvement earlier. Or if not maybe we could try dropping a beacon at openings in the walls.
I provide the conversation here, free of commentary.
g_ variant where CH_YELLOW becomes a strict food-verified lane (painted only by recent food finders/carriers), then add an explicit anti-stampede gate so only a controlled fraction of ants lock onto it.This was an explicit instruction, both in CLAUDE.MD and in my opening conversation with Codex. "When debugging, look at the ant behaviors before forming a theory." I knew the importance of actually running the tests. What I had not conceived, not considered, is that for an entire day, my entire fleet of agents had been writing broken code, and smuggling in false assumptions to avoid doing any debugging work. Not one instance of Claude code had actually seen if their code worked.
I was not angry.
Not even as I realized that every single assumption encoded in memory and in the experiments.md could not be trusted, because the multi-billion dollar brains that will one day take over my job couldn't be bothered to follow one of three basic instructions I had laid out.
No. 'Anger' was too moderate a word. 'Incensed' didn't quite capture it either. I'm not sure there's a word that captures "furious at myself, and also the tool I'm using, and frustrated at the waste, and I want to fire myself and this computer into the sun." Because I couldn't be mad at the billion dollar lying machines. I knew they lied, and like a sorcerer tricked by a demon, I hadn't read the fine print. I had wasted an entire day, burned a fortune in tokens that had generated pure fiction and worse, I had to rebuild the entire accumulated knowledge base.
It took six iterations. During which Codex stubbornly refused to look at ants unless I grabbed it by the scruff of the neck and told it that it must eat its vegetables. It was pure agony, but I barely felt it, I was simmering with rage, and I was convinced the idea was good. If the code hadn't been such a twisted mess by this point, it would have been faster to write it by hand, but it had become inscrutable to me.
I once again provide a transcript:
v282. It is not a corner case; it's a straight vertical yellow segment where the code reverses because the back edge has lower intensity. I'm patching only that demonstrated bug: on a straight lane with no side exits, keep going forward and never use intensity to justify a reverse.v282 as the anchor and only applying narrow, trace-backed fixes from here.We had broken the 600 point barrier. We had broken into the top 10.

This is the reason one embarks on a journey like this. For that moment of exhilarating triumph. It was 7:20 am on Sunday. Somehow the minutes had faded into hours. The time between 2 am and 7 am had me wrestling with ChatGPT and finally, finally learning the incantation to bind it to my will.
I had to wait for someone to take over the baby shift anyway, he had been sound asleep as I fought with the code, with the agents, and with myself. So for the next hour we fixed the remaining bugs. Some edge cases caused infinite cycles, others caused ants to repeatedly bounce off of walls, and as bug after bug was fixed only the ants remained. The score climbed to 678 points. Seventh place. Dave celebrated with me on Discord.
Next, dethroning simonwongwong.
Vali-ant Effort
The gap was now a hundred points. Every break-through so far had netted no less than 70. We were one breakthrough away, and then off to Hawaii. Where there would obviously be a parade in my honour.
It's important to keep your fantasies rooted in reality, after all.
The real issue is we were now running into the ragged edges of assembly. There hadn't been that many registers to begin with, and they were all serving multiple purposes. r6 was used during wall following, coopted during Lévy walks, stolen back as a temp register when you transitioned from wall following. Every bit of data you wanted to store had a real, terrible, tangible price.
If you wanted to store something as simple as am I left-handed or right-handed? so you could toggle it later, you had to give something else up. The registers were packed tight. An i32 can hold a surprising amount of data if you're willing to think in binary and carve it into little segments for different pieces of state. The more you do that, the more likely it is that one day you store something very important, shift everything by one, and your entire colony starves while walking in circles.
Worse, there was a strict limit of one thousand instructions per program. The initial wall following breakthrough program had clocked in at 683 instructions. When we scored 678 points we were at 913 instructions. Wall following alone consumed 174 instructions. Every time I tried to get clever about it (or worse, Codex and Claude assured me an instruction was unneeded) we would get a 200 point regression and ants bouncing off walls like demented ping pong balls. It got to the point where I could predict the flavor of failure that tweaking a specific set of instructions would cause. Touching r7 always wound up with ants circling the outside wall forever. Every time we tried to change yellow following we'd wind up with dancing ants that refused to deliver food.
More and more of my time went not into testing whether a new idea worked, but into figuring out exactly how we had broken existing functionality. I was the captain of a boat that was more holes than boat.
The question "have you looked at the ants?" became a staccato mantra I typed after every new conclusion Claude reached. The answer was almost always some variation of: "No, I'll do that right away."
Millions of tokens, but only eight registers and one thousand instructions. Agents walking in circles like ants. It had a twisted symmetry.
By Sunday night, I got another message I had not been looking forward to. I had finally exhausted my Codex quota. I could either shell out 180 dollars for the premium tier, or wait a week.
Or I could cheat. That was an option too.
If you don't follow the development of coding harnesses closely, you might not know that Anthropic has what one might charitably describe as a rapidly evolving policy on CLI usage. Someone less charitable might call it arbitrary and actively destructive.
I wasn't about to risk getting banned from Anthropic. OpenAI, on the other hand, has more of a reputation for playing things fast and loose. So I signed up for a second OpenAI account, paid another twenty dollars, and resumed my Codex session as though nothing had happened.
If that was a ToS violation, I had no real way of knowing. Nobody seems able to clearly articulate what the terms actually are for agentic coding harnesses, especially once you involve OAuth-authenticated services. I figured I could probably get at least a day of coding out of it before I had to burn the last 5% of my Claude quota.
Or switch to Gemini or Grok, which was just choosing to surrender.
I was pleasantly surprised that it worked and I was not immediately banned.
There was no time to rest on my laurels. I had acquired the bare minimum required to continue the work. Without an oracle I knew I'd spend the next few days stumbling in the dark, strangled by registers and instruction limits.
The leaderboard had moved on. I was down to 13th place. There was no score below 700 left in the top ten, and the top of the board was now sitting above 800. Dave was making incredible progress on his Rust emulation layer, and while we agreed it was a very hard problem, I was half convinced I'd see his account appear on the leaderboard at any moment.
I still had several promising ideas, and I began working through them, one at the time. I couldn't parallelize the way I once had. The dearth of tokens forced me to work with a single agent, like some kind of caveman from the distant year 2025. So I explored them in order.
I did permit myself to burn a little of the remaining Claude quota on the side. Surely the promised 10x usage over the pedestrian Pro users meant that the last ten percent of my weekly budget would last me through the remaining four days.
Fate seemed determined to keep me from my destiny. I had to actually work at my day job, instead of moving ants around a map. Groceries had to be acquired. Dinner had to be eaten. In the background, ants carrying food, ants lost on the Fortress maps, ants following the wrong walls on Gauntlet.
To say progress was halting at this point would be generous. Every idea required cutting something else, fighting over registers, and making compromises that satisfied no one. Features would test well, yield a respectable ten-point gain, and then get cut immediately, because our last hundred instructions needed to buy us more than a hundred points
At around this time a mysterious figure showed up on the leaderboard. Someone with the Moment company logo. Out of sheer curiosity, I googled the username, and found he did work for the company, and… he had an open source repo with a high level language wrapping Ant-sembly. Basically what Dave had been working on. A holy grail. A tool that would free me from the tyranny of registers, and guide me back to the promised land of abstractions.
I looked at it, considered the full re-write, and made the type of decision that makes absolutely no sense to someone who isn't in the moment. I would either win with my cruddy, overwrought ant-ssembly, each instruction carefully and lovingly managed, or not at all. I rejected the temptation of a higher order language. I rejected the promises of not having to pack more binary into an already overloaded register, of not having to sequence my code to minimize jumps.
Victory or death. No other path existed.
Dave agreed.
And it would be death.
Seventh was the best I would do on the leaderboard. Over the next four days I fell as low as thirtieth place, clawing my way back to a modest 706 points by the end of the final night.
I could have stretched this out and kept you in suspense, but you've already stayed with me for 7,000 words. There is no picture of me on a beach with a fruity drink and a book about ants. rosewang01 won with 857 points.
I had hoped my nemesis-who-didn't-know-I-existed, simonwongwong, would at least have the decency to win. Instead, I believe he landed around 11th.
Dave placed 117th, with 305 points. He did indeed get a Rust emulator running after three days of work, with a total speedup somewhere around 100x the native single-threaded Javascript implementation...but he spent so long building the perfect tools that he burnt out before using them. Genetic programming turned out to simply not be a viable approach when code efficiency mattered this much; he said later that the only good things to come out of the approach was the fact that the actively modified ant-ssembly programs were mut-ants...as opposed to the reference ant-ssembly programs on disk, called const-ants. His plan to build a separate state machine for each individual ant ran face-first into the one-thousand-instruction limit. Which, to be fair, was not stated anywhere; it was simply a wall I discovered when I ran into it. His Rust implementation allowed for large parametric studies of code constants, and automatic dead code removal (by simply removing each line, one after another, to see if the result on any map changed); those things are great if you have an approach, but they are not in themselves an approach.
And, perhaps, he was never quite as captured by the ants as I was.
There is no clean narrative bow that ties this up. My obsessive desire to ram myself against the ramparts of Ant-ssembly did not yield victory.
I'd like to say that what mattered was what we discovered along the way: that I learned a lot about ants, large language models, and the right way to structure a project. That the time we'd spent galliv-ant-ing around fighting with registers had been worth it.
I did learn those things. It was worth it.
I also wanted to win.
I would have settled for top ten. Thirtieth is… fine. Respectable. Good, even.
I have to confess that I hate it. It's good enough that it should be satisfying. But it's not a win.
Next time I will throw myself at the problem with better tools, better ideas, and better mental models.
Next time I will win.

What follows is several thousand words about ants, maps, failed approaches, assembly tricks, and a generally unstructured chaotic mess. If you don't care about those things, skip to my reflection on the state of agentic coding, or scroll to the very bottom for the picture of me on the beach with an ant tattoo.
Lay of the Land
Let's start by breaking down the maps. There's twelve of them, and I've mentally broken them into four categories.
Open
Open maps are defined mostly by the absence of walls. They are theoretically the easiest maps, and we got full points on Open fairly early, but "easiest" here is a relative term, like asking which mountain is easiest to climb. It is still a mountain.
Open is the obvious example: the only wall is the edge of the map. Prairie belongs here too. The difference is in the food layout. Open asks whether you can exploit dense clusters. Prairie asks how you handle food that is spread across the map.
Field is similar. The walls are sparse enough that they are not a serious obstacle, but dense enough to ask whether you have thought about walls at all.
These are almost the tutorial levels.


They are also an incredibly useful baseline. Field will quickly tell you whether you've developed some wall-obsessed pathology, and if your score drops significantly on Open, you have almost certainly broken something fundamental that has nothing to do with gradient density, stampedes, or other fancy theories.
The lesson these maps teach is that the simulation has two core problems: exploration and exploitation. First, discover food. Then, bring it home. Everything else is really just set dressing around those two tasks.
Gates
The maps in this category are Chambers, Islands, Bridge and Pockets. At first they look quite different. Chambers is a series of rooms connected by wide passages. Islands is made of thick walls separating individual regions of treasure. Pockets consists of rounded enclosures with gates scattered across an open field. Bridge has a massive wall down the middle with a few gaps in it that allow ants to move between the two chambers.
What they test is whether you have thought meaningfully about walls. Specifically three things:
- Can you follow walls to find rooms you'd miss if you were randomly exploring?
- Can you guide ants back through those paths?
- Is your thinking about direction only considering manhattan distance (literally the x and y distance)?
If you don't have a good wall following strategy, even chambers, which is the easiest of these, with the widest passages, will have cohorts of ants determinedly bouncing from wall to wall in the main chamber. If you only consider Manhattan distance (or don't handle curved walls at all), the concaves in pockets trap you in endless cycles of trying to get home and rapidly switching direction.



These are the maps that ask whether you actually solved walls, rather than merely noticing they existed. They care how long you wall follow, what you do when you stop, whether you can escape corners and curved structures, and how naive your implementation really is.
I knew we had seriously solved a large part of walls when Chambers became solved, though Islands always remained a middling contender, requiring an exploration strategy that never quite developed sharply enough.
Dense
Only two maps in this category, and they're both similar and radically different. Maze and Brush.
Maze is what it says on the tin, a labyrinth of passages two ants wide that spawns into infinite dead ends, three way junctions, repeated cycles, and forces ants to overlap and manage being in close proximity. The food is pretty evenly distributed throughout and a good score demands that your exploration technique dives deep into searching instead of being satisfied with food nearby.
Brush meanwhile is the spanner in the works, the sadistic addition of a twisted mind that wants to punish clever approaches. It's just dense clusters of walls, jagged, random, scattered throughout the entire map. One out of three tiles is just wall. This creates a very different maze, and it actively punishes many strategies. Often I'd be encouraged by a result on Gauntlet, only to see Brush had dropped 100 points. Brush, out of all the maps, asks you if your techniques generalize, or if you've over-focused on the shape of a map.


These are both different enough from the preceding seven maps that they demand sophistication from your ant-brain than the earlier maps did not. I think it's perfectly possible to achieve a perfect score with the same brain on the first seven maps. I'm not sure if it is possible with Maze and Brush in the mix.
Nightmare.
Within the challenge constraints - eight registers, one thousand instructions, two hundred ants, two thousand ticks - I'm not sure it's possible to get a perfect score on any of these maps.
Of these, spiral is the "easiest" and by that I mean that the food distribution here is generous. That alone means that the strategies that work on pocket and brush will get you the first four-hundredish points. Spiral is a large set of concentric walls, with large gaps, which I call gates. Your nest begins at the center of the spiral. The food is evenly spread out which means that you can get a lot of it without having to reach the outer walls. The walls are round, and wall following the wrong direction means a very long trip to reach a gate. The further you get from the center, the more punishing that is, which means the food on the outer edges is almost impossible to collect in only 2000 ticks.
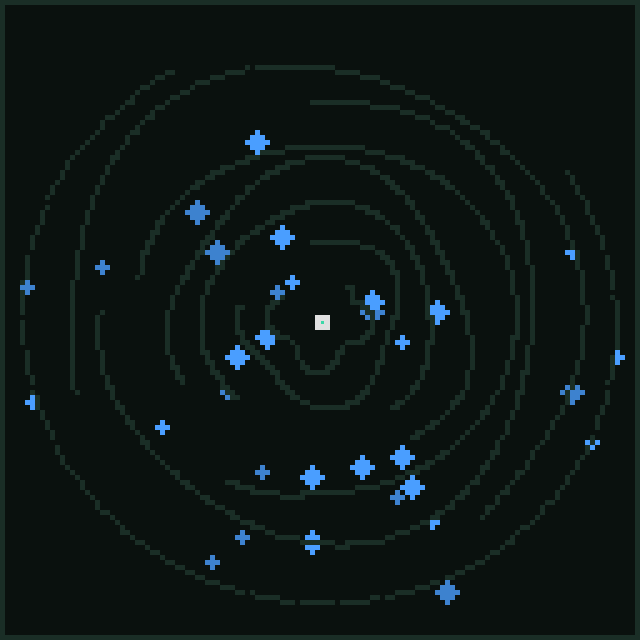
On the other hand, fortress is the exact ant-ithesis of this. Same rounded spiral walls, same very long walks, but your nest starts in the far corner, and the food distribution is cruel. There's "only" three walls, which is the only concession you are given. The vast majority of the food is at the center of the fortress, and if you can't reach it and exploit it, you will not break 70 points with the pittance that is offered outside of the main vault.
I spent eons analyzing fortress, and I'll talk more about specific techniques I tried later, the absolute best I could get if I just ignored all other maps and decided I only cared about fortress was around 300 points. Less than a third of the food. At the cost of tanking every other map.
Fortress was a rock that broke some of my best ideas. The core question it asks is simple: can you find efficient paths for exploitation? If you can't, your ants will never make it home in time.
Which, interestingly, is also the question Gauntlet is asking, just in a different way. Gauntlet seems, at first, like a larger version of islands. Five chambers in sequence, split by vertical walls with small gates.
Do not be deceived. The shape of the map means that if you pick the wrong direction trying to return and just follow the wall, you must traverse the entire perimeter of the map, with the addition of up to four walls. An eternity in our limited 2000 ticks. Naturally the food is spread out more towards the later rooms, which means you have to explore all the way there.
These are the maps that test not if your techniques work but rather how efficient they are, and if they actually have considered the cost of the different obstacles. For the most part, the answer I gave to that question was "yes, but obviously not hard enough."
Herding Ants
We're going to biopsy my code. What worked, what didn't. How it worked. By the time you're done reading this, I hope you will understand not just the how, but the tension inherent in the design. Because the true meat of the exercise is in how you balance competing priorities, and juggle the limitations of the space. Yes, we're going to read code line by line, block by block, harkening back to the distant past where that's how people developed and understood software. I promise it's not as bad as it sounds.
I am assuming a passing familiarity with the constraints of assembly here, but if you're not familiar, assembly is the most basic code you can write short of modifying binary directly. There are four things to keep in mind.
- Registers are your only variables, and there's a fixed number of them. There's no
my_variable = 5. You haver0throughr7and that's it. They'rei32s. - There's no structure. No functions, no loops, no if/else blocks. You have GOTO (jump to line X) and conditional GOTOs. Every loop, every branch, every subroutine is built from those two things. An if statement is literally just "skip over this block of code if this condition is true"
- Instructions do one tiny thing. Adding two numbers is an instruction. Comparing two numbers is an instruction. Moving a value from one register to another is an instruction. Which means encoding a variable so you can pack it into a register can be ten instructions. We only get 1000 of these total.
- There's no memory beyond the registers and the constants. I mean, in regular assembly you can and should use RAM. Here we have
r0-r7. A wealth of memory.
At least we won't have to worry about accidentally causing any segfaults or having linker errors, so we're actually ahead of the curve compared to where most assembly developers have to start.
Canny readers will notice this is not the full 927-instruction file I submitted three minutes before the deadline. As I reviewed it line by line for this post, I cleaned out dead code and a few bits of purely historical cruft so the final logic would be possible to follow. I've called out those changes where they're forensically interesting, but raw assembly is hard enough to read without also having to remember that wall beacons didn't work, or that jmp scout_logic really points back at m_loop.

